

Introduction - End-to-End Machine Learning for Real Estate Price Prediction
Machine learning is an extremely powerful tool, applicable to an astounding breadth of use cases. Today, almost any question imaginable can be the starting point for a machine learning project.
- “What products should we recommend to customers to complete their order?”
- “What will stock prices be tomorrow?”
- “How much should this house cost? How can we better estimate prices?”
This last question was especially interesting to us in the context of Spanish real estate. Spain is a diverse country, with tourist-haven islands and coastal towns, aging mountain villages, big cities, and everything in between. This makes it a very interesting case study and challenging prediction problem.
Starting with this question, “What is that house worth? How can we better estimate its price?”, the first step is to gather the data needed to answer it and develop a modeling plan. These are the first steps in the well known CRISP-DM process for data science — business understanding, and data understanding.
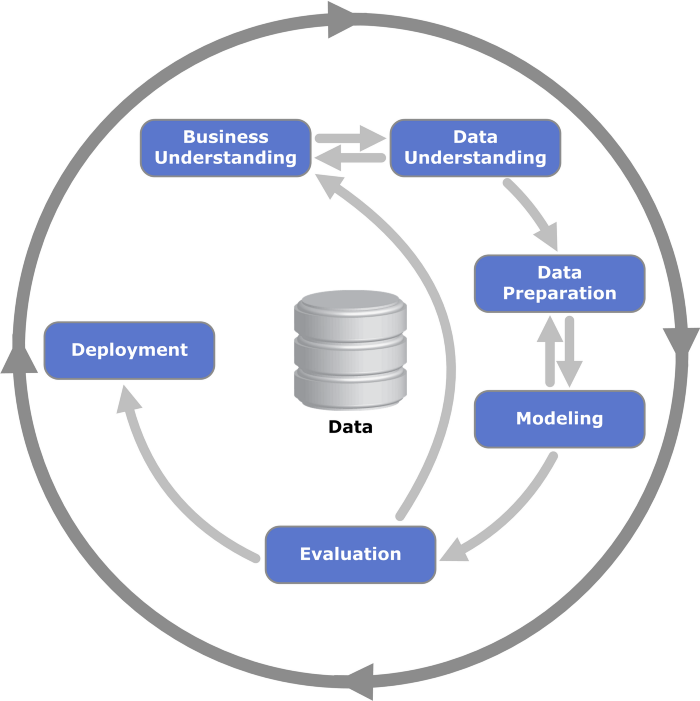
Once we have the data, we can assess which data preparation and machine learning methods will help us answer this question. The articles in this series dive deep into each step of this process, including data preparation, modeling, and iteration on these steps based on evaluations of the models in order to find the best possible model for predicting Spanish real estate prices.
Getting the data
Real estate is a topic with a wealth of information online — but often not in an easily-accessible public format. It would be very difficult if not impossible to find up-to-date information about real estate listings freely available on the web in a format that’s easy to work with from a data science perspective, like a CSV. Instead, data like this is often stored in a format that’s more human-readable and less machine-readable, like flashy advertisements on a website.
How can the data hidden in these advertisements be used to help us estimate real estate prices? What other data influences prices? Is all of this data included in the advertisements, or do we need to find additional data on the web?
We start by showing how we acquired the initial real estate data using web scraping in article 2, Webscraping Real Estate Market Data.
Gleaning information from the data Once we have scraped this information from the web, the next step is to transform this human-readable data into a machine-readable format. We start this process by removing data that we don’t want to use in our prediction model — this helps streamline the data processing steps which come later.
Removing unwanted data or data that is not applicable to modeling is shown in article 3, Outlier Detection. After these datapoints are removed, features are extracted from the data. Features are individual categories of information that each datapoint contains. These features together tell a story about the datapoint and are used for prediction the target variable. For example, features for predicting real estate prices include categories like number of bedrooms, number of bathrooms, location of the property, and indicators like whether the property has a garage. Article 4 in the series, Feature Creation, shows how these features were extracted from the raw data scraped from the real estate website.
As part of the initial analysis, unsupervised clustering methods were used to further understand the data. Clustering methods work by trying to identify previously unseen patterns in the data. Article 5, Clustering, shows the outcome of this unsupervised modeling and how the clusters identified can be used as a further feature for supervised modeling.
Initial modeling
Once the initial features were extracted and clustering was completed, we moved on to supervised modeling. All supervised methods shown are regression methods, as the target variable Price is a continuous variable. We began by training a simple multiple linear regression model as a baseline, then moved on to tree-based algorithms including Random Forest and XG-Boost. Article 6, Predicting Real Estate Prices, shows the results from this initial modeling.
Model improvement
Our initial models included only features from the advertisements that were already in numeric format , like square meters or number of bathrooms, or those that could be easily calculated with additional data found on the web, like distance away from a major metropolitan city. This meant that these models did not see any information nested in the advertisement text. The advertisement text often includes more detailed information about the location of the property, its condition, and additional amenities.
The next article in our series, NLP Part 1: Text Exploration, shows initial analysis of the text feature of the data, and how the text data was prepared for modeling. Article 8, NLP Part 2: Modeling with Text Features shows how these text features were vectorized using a TF-IDF vectorizer and presents the results from including this text feature vector in the model.
Conclusion
The final article in our series shows how the models which incorporate NLP features compare to the original models. We also present further next steps to take, such as deploying the model to make predictions on unseen data.